Chapter 10
A different way of looking at databases
Visualising a living database
Using a virtual cafe, for readers to comment upon each chapter as it is written, is a good way for an author to appreciate how people can interpret explanations in different ways. A case in point is the conceptualisation of a living database, where almost everyone who read the last chapter saw it in a different light.
After reading the last chapter, one reviewer wrote:
I'm still not quite clear on what Peter is proposing -> to keep track of the people generating the data (like a net phone book), or the data they are generating...?
Depending on what is shared, surely the data that is uploaded to the database (or a pointer to it, at least) would take a similar form to that data which is already on the web -> in which case the standard problem of relevance and quality of information is going to be a major issue.
Current search engines are getting better all the time, and we've already hit the 'search engine of search engines' barrier. Thus, I think Peter will require a different type/source of information for this project to work (if he's going to do what I think he's going to do...!)
Pete
This reviewer seems to be thinking in terms of a conventional database, where either the names of people, or the information they provide, is recorded by a database management system. This would see the purpose of the database as being a depository of information that is accessed by the users.
Although a living database can be visualised as working in this way, the conceptualisation is totally different. The function of the computer needs to be seen as providing only an infrastructure – a formatted, but otherwise empty space – where users can insert their presence.
The action would consist of users inserting their presence in places where they would be most likely to find people who can provide them with exactly the kind of service, help or information they need. In other words, the computer programming of the database isn't concerned with storing and providing information, it is about providing a landscape in which people can move around to meet each other.
This point was appreciated by another reviewer, Hubert Spall, an English Web site developer, who wrote:
The advantage of the Internet seems to be in the speed with which communication takes place, so, by using e-mail effectively we can network our business more easily. This is the case even if our main business is off-line. The web site then becomes a repository for information too vast to be discussed with each contact, customer or partner individually. The web site itself may have nothing directly to do with the business - no online selling involved, the product or service itself existing outside of any computer related area - but simply provide an information point for the real business.
In order to bring in business via a web site it is often necessary to provide a free information service about a whole lot of stuff RELATED to your business, but not leading directly to any sales - providing a facade of objectivity, the appearance (real or imagined) of a free service. And this is where costs begin to escalate...
The alternative model [the living database] provides a virtual environment which enables people in the specialised area we are interested in to find and communicate with others who have some knowledge or service they need. The use of intelligent agents allows searching for the relevant people to be personalised and specific.
Hubert Spall
Another reviewer, Mary Rickman-Taylor,from the Arizona Institute of Business and Technology, also realised that chapter 8 was about providing an environment where people could find each other. She viewed the living database in a more abstract form:
Chapter 8 pulls into tangible reality what perhaps many of us have been doing as we have been going along. In a sense the n- dimensional people space will become the "super group" that writers have promoted for years as being one on the tools for success. That is, the collection of people that can help one move in the direction of successful endeavors, of solutions to problems that are not amenable to easy solutions by the limited means of a small group, but that can be approached in the people space referred to in Chapter 8.
Mary Rickman-Taylor
Mary Rickman-Taylor had realised that chapter 8 hadn't been about storing information, but, about devising a strategy to find useful contacts. Throughout this trilogy, constant stress has been laid upon the need to deal with people rather than information. This is because information and knowledge in the world of technology is continuously changing, expanding and evolving. It has the appearance of a fractal: the more you know, the more you find there is to know. Every branch of knowledge has innumerable niches and every niche has innumerable branches. Only humans can deal with this kind of dynamic complexity and they do this by interacting with each other and sharing knowledge.
Computers are undoubtedly ideal devices for handling vast amounts of information. Hierarchical branching can be employed to store and retrieve data according to specified categories or divisions of categories. However, if the information is undergoing continuous evolutionary change or the organising structure becomes unstable, intractable problems arise.
Considering the bricks and mortar example, described in the last chapter, the system of retrieving particular garments from piles of miscellaneous cast offs looks as if it can be modelled in the form of a regular database. Suppliers, buyers and products can be listed and categorised, and it would seem relatively straightforward to create relational links between them. However, if such a database were to be used in a real world situation it would be subject to continuous dynamic change due to unpredictable fashion swings.
To explain, think of current fashion creating a demand for long skirts. This would create a concentration of interest in that particular garment area, with buyers looking for rag merchants sorting out long skirts and rag merchants responded to the market demand by selectively sorting for them. Then, for no logical reason, fashion might suddenly switch to short skirts. This would cause all information concerning long skirts to become redundant and the database would have to start reflecting the new interest in short skirts.
Then, skirts might go out of fashion altogether as ladies turned to wearing dresses. Interest in skirts would evaporate, as people would then want to know everything there is to know about dresses. If this volatility of interests is happening all the time, it would be totally frustrating for database managers, who would be continually revising and updating the content and organisation of their systems.
The paradigm shift, of visualising a people space instead of a conventional database, would completely remove all problems associated with information volatility because there would be no information to change. Instead, there would just be a framework of designated areas where people meet . When information needs change, people simply move their presence to new areas in the space where their new information needs can be met. For example, if interest changes from skirts to dresses, people would simply move their presence from the areas where skirts are being discussed to the areas where people are discussing dresses.
The database function would be minimal: simply to register the current locational presence of people as they choose to move between different areas of interest. These locational changes would be instigated by the people themselves: the database simply recording their current choices.
Keeping up with trends and fashion
It is probably easier to visualise this not as a conventional database, but, as a formatted space of initially empty areas. When a new topic of interest emerges, anyone can spontaneously label a new empty area with the name of that new topic. Anyone else interested in the new topic can then move their presence into that area so as to be in contact with others interested in discussing it.
In this way, the overall people space would see new areas of interest continuously coming into existence, as and when fashion changes or new trends emerge. People could move between these areas according to their changing interests: leaving one area to go to another. In this way, it wouldn't matter how dynamic or changeable the information base is, the conceptual framework would simply reflect a population of people moving around to different areas within a formatted space.
Treating this situation as a conventional database, would see it as being similar to that of trying publish a book that listed all the trendy meeting places in London. It could be up to date at only one particular moment in time. By the time the book was printed, new meeting places might have become fashionable and those listed in the book may be out of fashion. This would cause the book to be an inaccurate source of reference. Imagine now trying to create such a book that tried to record the currently trendy meeting places of every town and city in the world; this would be nearer to the scale of the problem that we are trying to deal with.
Despite the near impossibility of being able to create up-to-date directories of currently trendy places where people are meeting in various parts of the world, these gatherings do take place and quite obviously the people who are there have discovered where they are being held. It is this enigmatic process of knowing where things are currently happening that needs to be accommodated in the formatted structure of a living database.
London can be viewed as a formatted space, where trendy meeting places suddenly and unpredictably become popular. This view would see movements of people as they moved on mass and for no apparent reason from one venue to another. The only certain way to keep track of the movements of any particular group would be to be part of that group: so that you can move with it when it moves on.
It is the essence of this dynamic scenario that needs to be created to ensure that people can find out where the current action they are interested in is happening. The information is irrelevant. The most important issue is being in the right place at the right time. This will have to involve being in regular contact with the right kind of people.
From the general to the particular
Let's look now at the problem posed by Tillman Pearce. How can cancer patients be helped in finding out about all the treatments that might be available to help their condition?.
The treatment of cancer is a typical example of a rapidly expanding technological field where new research is continuously creating an abundance of new developments in many different parts of the world. For a patient seeking treatment, it would be impossible to keep track of all the activities taking place. Realistically, a cancer patient couldn't be expected to study all the technical papers relating to their condition. Neither could it be expected that they'd be able to discuss matters with many specialists. As discussed already, any databases available to them on the subject would almost certainly be incomplete, probably out of date and unlikely to address their specific individual situation.
The only option left open for them is to mix with other cancer patients who have a similar condition and find out what is happening to them. This is where they can be helped: by providing them with a formatted space where they can get together in niche groupings to pool their knowledge. After all, collectively as a group, the patients are as much aware of all the possible treatments as the physicians.If a conceptual framework can be designed to arrange for cancer patients with a similar condition to find each other, this would be far more valuable to them than any informational database. They can compare treatments, swap, information. Many of them will have built up specialist knowledge on their condition that they can share with the others. Perhaps some of them will have Web sites, where they have recorded the extent of their knowledge within the niche area of their particular condition. Between them, the patients are likely to have more experience and knowledge of treatments and outcomes relating to their condition than most individual cancer specialists.
If special areas of interest are created in a people space – relating to different types of cancer, types of treatment and other associated topics - it is likely to attract more than just the patients themselves. It will also attract friends and relatives who use the Internet to help find the best treatment for their loved ones. It will be of interest to researchers, drug companies, doctors and surgeons who will have a professional interest in knowing about the work of others and the treatment options outside of their own particular approach.
Visualising these communities as forming spontaneously in a formatted space – with changing circumstances and new technological developments causing them to move around, dividing them up into more specialised grouping as their number increase – would seem to be a far more realist approach to obtaining knowledge than trying to create a conventional database of information.
As we shall see later, this approach can be usefully applied to many other areas of technology – especially where there is an impossibly large knowledge base that is continuously changing, expanding and evolving.
The ubiquity of empty formatted space
The idea of starting with an empty formatted space and allowing areas of interest to form spontaneously through the activity of users may seem somewhat esoteric, but, this is the principle behind a living database. To begin the explanation, let's start with the formatting of a space.
In the world of computing, the formatting of an empty space is common to all computer hardware and software applications that deal with memory and information storage. The most well known example is the formatting of a hard disk. The general idea is that a certain volume of memory space is available or allocated and this is divided up into small sections that are individually identified and kept in some form of order so that each section can be accessed irrespective of its label or content.
After the formatting process, any information that is put onto the hard disk is divided up between a number of these small sections. The identification numbers and sequence of these sections are recorded by the operating system, so, that it knows where to retrieve the pieces and put them back together again whenever it is called upon to do so.
With this system of pre-formatting the disk with small empty sections, files and applications can be broken up and stored on the disk using any sections that are currently free. This method of storage might seem bizarre, but, it is an efficient way to store information that is constantly being changed, added to, deleted or replaced because the storage can be distributed instead of being confined to a fixed area. The operating system has no problem with a file being broken up and distributed in different places all over the disk because it knows where every section is located, so, any file can be retrieved as easily as if it were stored in one single section of memory.
Software applications that need to create their own formatting system can overlay the formatting of the operating system with its own ordering arrangement. i. e., the operating system allows an application to create its own formatting and will then transparently convert this to its own system when saving to disk. When the application wants to access the information, the operating system will retrieve the data in a way that preserves the formatting arranged by the application.
This method of storing files allows all applications to use their own formatting systems, so, databases can hold information in a format that is most convenient for the algorithms they use.
More sophisticated formatting can attach little computer programs to each of the separate formatted areas that are created by an application. This can be seen in spreadsheet programs that, although appear initially to a user as completely empty grids of rectangles, are in fact formatted arrangements of complex cells that are able to communicate with each other and be linked in highly complex ways.
Computer programming languages always have facilities for formatting a memory space in any way defined by the programmer. High level, multimedia authoring programs present the developer with a pre-formatted empty space into which can be slotted, software modules, text, graphics and sounds. It is the existence of pre-formatted space that makes it possible to use object oriented design strategies because through the arrangement of the formatting, objects know where to send messages to each other.
These are just a few examples of the ubiquity of the concept of a formatted empty space and the various ways in which it can be employed. The essential idea to grasp is that the way in which a formatted space can be used is limited only by the imagination.
Growing into a space
A conventional database design approach will be to create a formatted space to suit algorithms that will be used to sort, search and form relationships between the data items. A human database designer will work out what the categories and sub categories of the formatted areas should be, so that data and information can be inserted into places where the algorithms are designed to expect it.
A living database cannot be constructed in this way because the initial assumption would be that no one has any idea at the start as to what kind of information the living database would be dealing with, let alone knowing all the categories through several levels of subdivision.
My own approach to the construction of a living database was to first create an empty list of twenty-six lines – each of the twenty six lines being identified by the letters of the alphabet: A to Z. This then became the template for the formatting of the entire living database.
When any line is clicked upon, it will either point to a particular area of the formatted space described by the line, or, present another different but identically looking list of twenty-six lines lines identified by the letters A to Z. These line can then be used as subdivisions of the topic described by the line that has been clicked on.
Presenting new lists of lines when categories need to be sub divided allows the database to expand at a second level to a total of 26 times 26, equalling 676 lines. Clicking on any of these 676 lines can present yet another different but identical list of twenty-six lines: allowing a total number of lines at this third level of 26 times 26 times 26, equalling 17,576 lines. Extending this to five levels would allow a total of 11,881,376 lines: creating a structure that can format any space into nearly twelve million different possible topic areas.
Of course, it is extremely unlikely that any area of knowledge would need twelve million categories, but, that is not the point. The idea is that this formatting technique allows ample room in which to expand the content of a living database in many different directions according to the most appropriate way to sub divide it up.
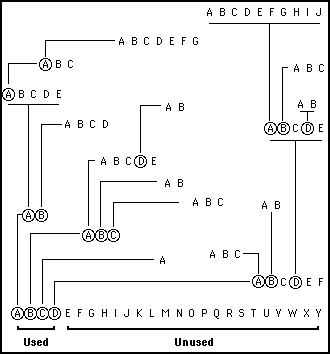
For example, one level may use only two or three of its possible twenty-six sub categories. Many sub categories may not extend to the full five levels. However, with such a large possible space in which the content can extend, the content has the freedom to grow to any size and shape of tree like structure that conveniently divides up the total subject matter. Figure 10.1 illustrates a typical tree like structure expanding into a formatted space from a first level that uses only four of the possible 26 categories available at that starting level.
Figure 10.1
A living database where sub division of categories are creating a tree like structure within a formatted space. The circled categories are those that are sub divided. The others are pointers to particular areas in the space which contain information (or people)
Figure 10.1 shows a database consisting of just four categories at level one. Each of these sub divide. Some of these sub divisions divide several times, creating new levels where at each there might be more sub divisions. Category "A" of the first level through the route of sub divisions "A,A,A, A" points to seven sub divisions at level five.
From this figure, it is easy to see how billions of possible sub division arrangements can be grown in this formatted space, which has twenty-six possible sub divisions at every branch at every level.
The advantage of this system is its elegant simplicity. Any tree like structure that might grow as a result of adding and subdividing categories of the content will be constructed of multiples of exactly the same simple template of twenty-six lines. Using an object oriented environment that can use a templates to create components on demand, there will be no need to create these lists until they are actually needed.
It might seem that there would be a problem in addressing or trying to locate any particular area in a space containing up to 12 million of areas. However, the modular nature of the formatting of the total space allows an elegantly simple solution to this problem. Each of the areas can be described by the route taken to reach the area from the first level.
Addressing any of the twelve million separate possible areas in this space requires a maximum of five letters: the route description from the first level. For example an area at level five in this twelve million area space might be described as "CKRAY". This would indicate that category "C" was chosen at the first level, category "K" chosen at the second, category "R" chosen at the third, category "A" chosen at the fourth and category "Y" chosen at the fifth. This address would identify one particular area out the the possible total of 12 million.
If this formatting scheme were used to describe areas where people could meet to discuss a particular topic, this simple addressing system would not only define a particular place to meet to discuss one, out of a possible 12 million topics, it would also describe how anyone could reach that meeting place to insert their presence and to find out who else was there.
With such a simple addressing system, it is possible to string several addresses together to describe being at several meeting places simultaneously. It is also a convenient form of addressing to include in the construction of a bot, so that it knows what places to visit on behalf of its owner.
Notice also that anyone can find a particular topic that interests them by making selections at each level: a maximum of five decision points. This is best explained with an example.
Finding a way through thousands of spaces
Trying to visualise a people space with 12 million different possible meeting places might seem impossibly complex. How, for instance, would people find the best areas to establish a presence, i.e., find the virtual meeting places where they could make just the right kind of contacts? Surprisingly, it is very easy: it involves nothing more complicated than answering a few multi choice questions: one for each level (Note: the levels correspond to the different dimensions of a multi dimensional space as described in the last chapter).
In the hypothetical example described in the last chapter, rag merchants could establish a presence at meeting places in a people space – where customers would be looking for the garments they were sorting – by answering the following five multi choice questions (selecting by clicking on a single line in each of five given lists – with each click bringing up the list for the next question):
1) What items do you sort? (12 items listed - A to L)
2) What is your geographical location? (12 items listed - A to L)
4) What is the type of locality you draw stock from? (12 items listed - A to L)
3) What languages do you speak? (10 items listed - A to J)
4) How many sorters do you use? (9 items listed - A to I)
The answers to these questions (requiring only five clicks) would automatically create a unique address at one of the possible 155,520 places in the people space. By repeating this simple procedure, a rag merchant can establish a presence at every meeting place where there are customers looking for someone like them and wanting to buy the products they are sorting.
In an identical way, buyers can establish their presence in the most suitable places to meet the right kind of rag merchants who are sorting out the garments they need– simply by answering five similar multi choice questions (again by clicking on lines in lists):
1) Select the type of garments you are interested in (12 items listed - A to L)
2) Select the geographic areas you can travel to? (12 items listed - A to L)
3) Select the type of locality do you want the garments to come from? (12 items listed - A to L)
4) Select the languages you speak? (10 items listed - A to J)
5) Select the size of company you want to deal with (number of sorters) (9 items listed - A to I)
Again, each meeting place chosen would require no more than five clicks, each click bringing up the next set of lists. This could be repeated for as many meeting places that the buyers wishes to go to meet appropriate rag dealers.
There will be no sense of the complexity of the formatted space; the users probably won't even realise it exists. They will simply be answering the questions and as a result find themselves automatically connected to the people they need to know.
This system matches suppliers to customers. As it is a virtual space, both suppliers and customers can go into as many spaces as they like, so, a rag merchant can appear simultaneously in several different places if they sort several different kinds of garment, or, speak several different languages.
Similarly, a customer can appear in many different areas if they need a number of different garments, speak several languages, be prepared to travel to several different geographic areas and don't care how many sorters the rag merchant employs. This exploits the unique property of the Internet to allow people to be in multiple virtual places at the same time.
Although this is a hypothetical and probably not a very practical example, it illustrates the essence of the general idea. It is not hard to adapt the conceptual framework to all manner of subject areas where it is useful for people to meet others. This will apply particularly where people need to meet others to be able to share information and knowledge.
Abstracting this model for other purposes
The rag sorting example involves the transfer of physical goods. But, this same structure can be used to bring people together people for the purpose of exchanging information or finding collaborative partners.
Imagine now, all the millions of people on the Internet. Imagine them each needing a special piece of information that somewhere some of the other millions of people on the Internet might have. Wouldn't such a structure be useful for bringing together those who need to have a particular piece of information with those who might have it?
Such a structured space could also be used to bring people who want to create e-businesses together with people who can help them. It can be used to bring people with software products together with those who have a need for those products. It can bring service providers together with those who have a need for those services. It can bring experts and specialist together with the people who need their specialist help. It can bring together people with money with those who need it.
Returning to Tillman Pearce's initial problem of creating a database for cancer treatment. Wouldn't this be a useful infrastructure to facilitate the flow of information in this particular subject area? Patients with similar types of cancer could meet to share experiences, exchange knowledge about treatment strategies, costs and locations of specialist treatment centres. As this could be made available to anyone in the world, it could bring in opinions and knowledge of practices and treatment facilities from every corner of the planet.
Meeting places could be established based upon any number of criteria, so that patients can go to special areas to discuss a particular treatment option, a promising line of research, methods of coping with pain, drug testing programs, etceteras. All it would take to set up a any new meeting area would be to add a new category to one of the lists. This can be done by the users themselves if they were given the facility (this would be the function of a bot, as we shall see in the next chapter).
Similarly, in any area where there are too many people or too much information to deal with, a tree like structure can be created in a people space to filter out fast and efficient routes through the confusion and noise to where solutions to problems can be found.
What happens at the meeting places?
Every route through a tree like structure in a people space will end at a meeting place where people can establish a presence and have an opportunity to communicate and interact with the others who are present.
For the moment, we'll skip over the questions of making sure there are enough people there to make it interesting, or, of getting the details of those who are present – these questions will be dealt with in the next chapter when we cover bots and overall system organisation and house keeping. Firstly, we need to establish what form these meeting places might take.
As there could be any number of these meeting places, they would have to be able to be created on demand, from a single template. Just like the list modules from which the trees are constructed, these meeting places would need to be produced as and when they are needed without having to use custom programming or call upon any human management system to make the necessary arrangements. When a user sees a need for a new topic to be discussed, they should be able to create a new meeting place simply by giving it a topic name and clicking on a button.
Having to use a single format for all the meeting places, it will be necessary for the design to offer a wide range of options for people to be able to communicate with each other in a variety of different ways. Many options can be covered by bots on the client side, but, for the moment let's look at the kind of template that can be provided to create meeting places on a Web site.
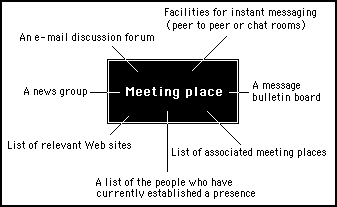
At a minimum, the meeting place would have to provide the following facilities:
1) A list of the people who have currently established a presence
2) An e-mail discussion forum
3) A message bulletin board
4) A news group
5) Facilities for instant messaging (peer to peer or chat rooms)
6) List of associated meeting places
7) List of relevant Web sites
This arrangement is illustrated in figure 10.2.
Figure 10.2
Each meeting place in the formatted people space will take the form of an environment in its own right, with various types of communication facilities provided. This environment will have to be designed as a template so that it can be recreated for every meeting place needed
At any particular meeting place, different facilities might be used according to the preferences of the people who have established a presence there. There is no way of being able to determine in advance what these preferences might be, so, all options must be offered so as to allow each meeting place to evolve in its own.
Individual communication strategies
The picture presented so far is of an open environment that anyone is free to join. Meetings and communications are public affairs with no apparent facility for mixing groups or for anyone to be able to selective choose people from different groups to have private discussions. This omission needs to be addressed.
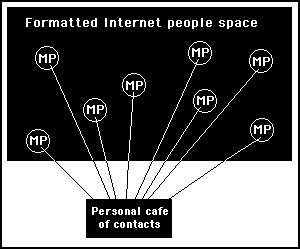
The simple solution is to combine the concept of the people space with the concept of a personal cafe of contacts. In this way, anyone can use the public meeting places to acquire contacts and then use the conceptual environment of their own cafe to have more private discussions outside of the public people space. This is illustrated in figure 10.3, where it shows how an individual can acquire a number of contacts from various different public meeting places, then add them to the list of special contacts they communicate with privately in the conceptual area of their own personal cafe.
Figure 10.3
By visiting various different meeting places in a formatted people space, a variety of different personal contacts can be acquired. These can then be conceptualised as appearing in a private cafe within the space of a personal computer
Although this cafe can be purely conceptual – with the cafe existing as no more than simply a list of people to communicate with privately – the cafe can be given a definitive form and substance. This has already been discussed earlier, with a more detailed explanation given in the second book of this trilogy (The Ultimate Game of Strategy). In essence, this involves creating a major list of all known contacts, out of which fifty special contacts are chosen who might be useful or directly involved in current activities.
If people use bots, created as clones of their owners, it is possible to insert these a presences in the meeting areas. This would allow direct transference of these bots, with all the information they might contain about their owners, directly into a personal cafe environment where they can be examined in private. Technically, this is fairly easy to arrange - as will be discussed in the next chapter.
Using components to produce solutions
The concept of a living database would seem to be a likely candidate for a basic component in a solution to help patients locate suitable cancer treatments. It is worth taking it further at this stage because this structure could become a very useful component in all kinds of e-businesses that involve putting people in touch with each other.
Biological evolution works in this same way. It is a continuous process of finding and developing new components that are then combined in different ways to create complex organisms. Few, if any, of the biological organisms we recognise today have evolved from scratch, they are all made up of components that have evolved independently in a previous evolutionary structure.
Biologists, have discovered the same biological components being used over and over again in different contexts and in different organisms. Looked at in this way, would see Mother Nature's evolutionary strategy as primarily that of developing components and then using them in different combinations for opportunistic purposes.
This takes us back to Sherlock Holmes' method of detection. He had built up a number of components he used for detection. One of these was his specialty knowledge of cigarette ash. He had this knowledge to call upon where it became opportune in helping to find a solution to the problem of who committed a crime. In a similar way, a fully developed, living database structure could be just the key component needed to turn an opportunity into a viable e-business solution.
Working in this way to create e-businesses, it isn't sufficient to have components that are just conceptual ideas. For a component to have any real value it must have been developed and perfected to the extent that it can be put to work immediately when an opportunity comes along.
In the fast moving world of e-business, this component building is happening all the time. The vast sums of investment money thrown at the early dotcoms at the turn of the century may have been a complete loss to the investors, but, what this money did was to create many little tried and tested modules that designers are able to reuse later by applying them to new situations.
Most professional programmers work this way. They never build software solutions entirely from scratch. They progressively build up libraries of modules that they can use whenever an opportunity presents itself. Most importantly, these modules have been tried and tested – even though it may have been at the expense of a client.
This is why it pays to use experienced programmers. Its not so much that they have learned to become cleverer and cleverer at programming (although this happens as well), their greatest value is that they can put together previously developed modules that can be quickly and efficiently combined and adapted to suit a new project.
Looking at the living database as a component – for me, this idea evolved out of a number of different life experiences. These experiences tell me that the concept is not complete or viable in itself as it can only be of value if used with a strategy to achieve a condition known as "critical mass".
Critical mass
With practically all Web based businesses, the key to being successful is to achieve critical mass. This has many definitions but they all boil down to the following:
Critical mass is the point at which there are sufficient users or customers for the business to be profitable, self running and self maintaining
Perversely, many of the failed dotcoms relentlessly pursued the goal of attracting as many visitors to their Web sites as possible in the mistaken belief that this would lead automatically to commercial success. It doesn't. This is not what critical mass is about. The only people who count toward critical mass are those who are benefiting from the site and also adding to the profitability of the business. It is the need to achieve this double goal with all visitors that makes it so hard to reach critical mass.
The only way this double goal – of both visitors and the e-business benefiting – can be achieved is by building a system that creates wealth, i.e., developing a non zero sum game situation where everyone can gain.
In the design of a Web based business, the primary consideration should be that the visitors, customers or clients should benefit substantially and directly. If this condition is fully satisfied, stability of the business can be assured. Only after this condition is fully satisfied can the business owners then start to consider how they might benefit themselves.
If the system is creating sufficient benefit or wealth, there is bound to be some way in which the business can find some way of profiting. After all, if someone creates a wealth creating situation it is only right and fair that they have a share. If there is not sufficient wealth created for both customers and the business to substantially benefit, then critical mass cannot be achieved. A point often ignored by those who create Web sites whose main objective is to attract eyeballs.
Benefit for customers or clients must be immediate, but, the benefit for the business often comes later – once the conditions for critical mass have been fulfilled. This will involve an initial capital expenditure, which will be needed to cover the burn rate (excess of outgoings over income) while attempting to reach critical mass. A prudent strategist would see this as the most important area to concentrate upon: even taking precedence over the technical aspects of the solution. This suggests a strategy of starting simple and leaving as much of the complexity as possible until after critical mass has been achieved.
Achievement of critical mass with systems like the living database is particularly difficult because it depends upon self fulfilment for success: a "chicken and egg" situation. Obviously, a business based upon a living database would have a great chance of success if the people who used the system could click their way to a meeting place and be guaranteed to find a useful group of contacts waiting for them when they arrived. However, the first people to arrive at a meeting place will be disappointed because there won't be many there.
Clearly, a strategy has to be devised such that in the beginning a sufficiently large number of people arrive at a meeting place at the same time. In other words, every meeting place will have an individual critical mass that has to be achieved and maintained before it can be deemed successful.
This again points to the advantage of starting with a very small niche grouping where marketing can be narrowly targeted and timing more easily controlled. Having successfully achieved one synchronised start for a meeting place, others can be added – one at a time - to gradually increase the number of meeting places which have exceeded the point of critical mass.
The necessity for every meeting place to have critical mass means having to wait until the number at a meeting place reaches some multiple of critical mass before it can be sub divided to create new categories or levels. Consequentially, the treelike structures within a people space must be grown rather than be predetermined or planned. This requires a bottom up strategy, which is fundamentally different from the top down way in which conventional databases are designed: where the branching and categories are mostly planned in advance of data being entered.
This makes sense because if one hundred categories were pre-planned to create one hundred meeting places the average attendance will be only one percent of the people using the system. This might see the first hundred people using the database all going to different areas and finding themselves being the only person there. Even a thousand people visiting a living database would find the meeting places they chose to visit being fairly empty and might conclude that the system wasn't worth bothering with.
A similar but slightly different problem occurs when an e-business tries to be too clever. Many e-businesses have failed to achieve critical mass because their system offers too many features, or, too many options, which confuses the users. A complex system that makes perfect sense to the designers, might be totally unfathomable to the intended clients. It is fair to conclude, therefore, that any Web based business has to be as simple as possible to use with all the technology completely transparent. Anything more complicated than clicking a mouse on easy to understand buttons is likely to put users off and lessen the chances of achieving critical mass.
This leads to the most crucial challenge for all e-businesses: getting potential customers actively involved. Or, to put it another way, why should any customer or client be motivated to use whatever service or product is offered? And, even before that, how do you get customers or clients to become aware of the service or product in the first place? These are not questions to be dealt with after a product or service has been developed. These will be critical issues that have to be included in the strategy right from the very beginning.
There is much to learn from the failures of the early dotcoms. Many of them developed an e-business solution and then spent heavily on advertising only to discover that the system they'd so expensively developed wasn't customer friendly, or, was so full of flaws that customers soon gave up on it. Many of them, in desperation, threw good money after bad by increasing their advertising or tried to patch up a system that was fundamentally wrong.
The living database concept described above offers an important advantage in this respect because it allows business systems to grow from a small base – a bottom up strategy. If you look back at figure 10.1, it can be seen to consist of many routes that lead to different areas of interest. This suggests that small sections can be isolated and developed independently of all the others.
A good strategy therefore would be to start very simply with one small section and develop this to a state of satisfaction before moving on to add others. This would allow concentration of marketing effort to be initially confined to one small niche area, which could be strategically chosen as being a group that is highly motivated to take part and is not expensive to contact.
When several meeting places have been established, more sophistication can be introduced. Experimental trials, of improvements or added facilities, can be tried out on single meeting places before using them on a wider scale. This, again, is a bottom up strategy of system development, which ensures that if intended improvements do not work out as expected, the success of the whole project isn't jeopardised.
Competition for critical mass
In the massively connected communication environment of the Internet, critical mass cannot be treated as a permanent asset. It is highly vulnerable to competition and changing circumstances and can disappear virtually overnight.
Unlike the world of bricks and mortar, people can easily and rapidly change their patronage if a new technological development outdates a business system or a competitor offers something better or cheaper. The only way to safeguard against this eventuality is to have a system that has low overheads and is extremely flexible and adaptable.
Low overheads will make it difficult for a competitor to compete on price. It will also reduce burn rate if the system has to adapt to any new and unexpected turn of events where critical mass is temporarily lost.
If a business system has a modular structure – such as a living database with many different meeting places – it is unlikely that all the modular sections will be affected simultaneously if critical mass is threatened. This will provide some stability to keep the business running while a strategy of recovery or adaptation is taking place.
### End of chapter 10 ###
Back to index
Note: This book lead to the creation of the stigmergicsystems.com website
Copyright 2001 - Peter Small
Email: peter@petersmall.net
All rights reserved by Pearson Education (Longman, Addison-Wesley,Prentice Hall, Financial Times for FT.COM imprint